나비어리 시스템 개발기 #4: 백엔드 - 도메인 이벤트로 표현력을 극대화하기

들어가며
백엔드 개발의 기초는 CRUD이다. 데이터를 생성하고(Create), 조회하고(Read), 수정하고(Update), 삭제하고(Delete)하는 것이 백엔드 어플리케이션의 기본적인 책임이다.
대부분의 웹 서비스는 이런 CRUD의 거대한 반복을 통해서 이루어져 있다.
나비어리 역시 마찬가지이다. ‘알이 부화하면 유조 데이터가 생성된다.’
간단하다. 알을 부화상태로 Update 하고 난 뒤 유조 데이터를 Create 하면 된다.
가장 간단하게 구현하는 방법은 아래와 같을 것이다.
class EggService {
@Transactional()
async hatch(eggId: string, hatchedAt: Date) {
// 1. 알 조회 (Read)
const egg = await this.eggRepository.findOneOrFail(eggId);
// 2. 알 부화 상태로 업데이트 (Update)
egg.hatch(hatchedAt);
await this.eggRepository.save(egg);
// 3. 유조 생성 (Create)
const chick = new Parrot({
type: "Chick",
eggId,
bornAt: hatchedAt,
...
});
await this.parrotRepository.save(chick);
// 4. 부모 쌍의 번식 성공 횟수 증가
const pair = await this.pairRepository.findById(egg.pairId);
pair.increaseBreedingSuccessCount();
await this.pairRepository.save(pair);
}
}기능은 동작한다. 하지만 어딘가 불편하다. 이전글 에서 다룬 바에 의하면 Parrot과 Egg는 엄연히 다른 어그리거트 루트이다.
브리딩 시스템의 도메인은 현실 세계의 연속적인 과정을 디지털 세계로 표현하는 것이다. 알이 부화한다는 것은 단순히 알의 상태를 변경하는 것이 아닌, 새로운 개체가 탄생하고, 부모의 이력을 갱신되는 등 여러 도메인의 연쇄적인 파급 효과(Side Effect)를 낳는다.
물론 나는 MSA를 하는것도 아니고 그렇다고해서 EggService에서 ParrotRepository를 주입받아 사용하는걸 불편해 하는 사람도 아니다. 하지만 Parrot을 생성하고 부모 쌍의 이력을 업데이트하는 주체가 EggService다..? 흠.. 이건 조금 불편한 것 같다.
결합도가 높아지고 절차지향적인 스크립트가 되어버린다. 그리고 알이 부화해서 유조가 등록된다는 도메인 로직은 그렇게 표현되지 않는다.
DDD를 통한 백엔드 어플리케이션 설계에서 도메인 이벤트(Domain Event)를 사용하면 이러한 사이드 이펙트를 훌륭하게 표현할 수 있다.
나비어리에서 백엔드 설계의 목표는 “성능”, “코드를 예쁘게 만드는 것”이 아니다. 현실 세계의 복잡함을 깔끔하게 풀어내는 것이다.
알의 부화, 유조의 탄생, 성장, 짝짓기 등의 일련의 흐름을 코드가 그대로 말해줄 수 있도록 하고 싶었다. 그리고 이벤트의 발행 주체를 도메인이 스스로 선언해야 한다고 생각했다.
서비스가 “이 알 부화했어!” 라고 하는 것이 아닌, 알 자체가 “나 부화했어!” 라고 말하는 구조.
도메인 이벤트(Domain Event)란?
도메인 이벤트는 이름 그대로 **‘도메인에서 발생한 의미 있는 사건’**을 의미한다. 보통 이미 발생한 사실이기 때문에 과거형으로 표현한다.
-
EggHatchEvent(X) ->EggHatchedEvent(O) : 알이 부화했다. -
PairRegisterEvent(X) ->PairRegisteredEvent(O) : 쌍이 등록되었다.
이미 발생한 사실을 기록하는 것이기 때문에 변경하거나 취소하지 않고, 그저 시스템 내에 “나한테 이런 일이 생겼어!” 라고 전파한다.
Side Effect는 우리가 생각했을 때 안좋은 것들만 생각하는 경향이 있지만, 실제로는 예측된 Side Effect와 예측하지 못한 Side Effect로 나눌 수 있다.
이런 경우 이 도메인 이벤트의 예측된 파급 효과(Side Effect)를 처리하기 매우 쉬워진다. 알 도메인은 자신이 부화했다는 사실을 알리고, 유조 도메인은 알이 부화했다는 사실을 듣게 되면 그 정보에 맞춰서 유조를 생성하면 된다.
이러한 느슨한 결합은 시스템이 커질수록, 도메인이 복잡해질수록 빛을 발한다. 만약 나중에 “알이 부화하면 예약대기자에게 알림을 보낸다”라는 요구사항이 추가되더라도 EggService와 다른 코드를 수정할 필요 없이 그저 EggHatchedEvent를 구독하는 메서드를 하나 만들면 끝이다.
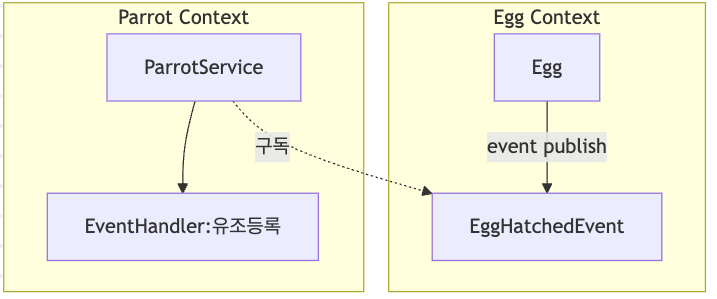
나비어리의 도메인 이벤트 모델링
그렇다면 이 이벤트를 어떻게 표현해야할까? 일단 나비어리 시스템에서 이벤트는 메모리에 휘발성 데이터로만 발행하는 것이 아니다. 추적할 수 있는 데이터로 저장할 수 있도록 하기 위해 구조를 설계했다.
@Entity({abstract: true, discriminatorColumn: 'type'})
export abstract class DomainEvent {
@PrimaryKey()
protected id!: number;
@Property()
type: string;
// 이벤트의 실제 데이터를 담는 페이로드
@Property({ type: 'text' })
protected data!: string;
constructor() {
this.type = this.constructor.name;
this.occurredAt = new Date();
}
// ...
}엔티티로 설정한 이유는 위에서 말한 것과 같이 휘발성 데이터지만 추적할 수 있게 하기 위함이다. 물론 미친듯이 많이 데이터가 쌓이는 구조에서는 추적도 거의 불가능하겠지만 (애초에 그런회사에서는 메모리 기반의 이벤트를 쓰지않고 kafka나 다른 메세지 큐를 쓰겠지..)
그정도로 쌓일 걱정은 하지 않기 때문에 일단은 이렇게 진행하기로 했다.
이걸 바탕으로 실제 부화 이벤트를 만들어보면
export class EggHatchedEvent extends DomainEvent {
constructor(
public eggId: string,
public hatchedAt: Date,
public hatchedWeight: number,
public speciesId: number,
public pairId: string,
public fatherId: string,
public motherId: string,
public inbreedingCoefficient: number
){
super()
}
}EggHatchedEvent는 부화 시점에 필요한 모든 컨텍스트를 담고 있다. 이제 어떤 알의 이벤트인지, 언제 부화했는지, 무게는 몇그램인지, 부모는 누구인지 등의 정보를 이벤트를 통해 알 수 있게 되었다.
이벤트를 주고 받는 방법
메모리상에 태울꺼니 혹시 모르는 상황을 대비해 db에 저장할 것이고, 추적 가능하고 유의미한 데이터를 담고있다는 것도 알겠다. 이제 남은 질문은 하나였다.
“이 이벤트를 누가, 언제, 어떤 트랜잭션 경계 안에서 처리할 것인가?”
흔히 이벤트 기반 아키텍처(EDA)를 말하면 Kafka나 RabbitMQ와 같은 메시지 브로커를 떠올린다. 나 또한 사용하고 싶은 마음은 굴뚝같지만 비용 문제와 유지보수에 필요한 리소스 문제를 생각하면 정말 오버엔지니어링의 끝판왕이라고 생각이 된다.
물론 운영이야 할 수 있겠지만 나의 본업은 이제 개발자가 아니라 브리더, 사업가이다. 나중에 SaaS화 하기위해서라면 모르겠지만 나의 개인 사업으로 인해 그렇게 거대한 시스템을 만들어서 유지보수를 하기 힘들게 하는것은 원치 않는다.
내가 선택한 도구는 RxJS였다. RxJS는 리액티브 프로그래밍을 위한 라이브러리로, 비동기 데이터를 스트림으로 다루는 데 특화되어 있다.
또한 RxJS의 concatMap을 사용하면 이벤트를 발행한 순서대로 처리가 가능하고, 트랜잭션 경계를 지키는 것이 가능하다.
이벤트 발행
export abstract class Aggregate<T> {
// ...
private events?: DomainEvent[]
protected publishEvent(event: DomainEvent) {
this.events = this.events ?? [];
this.events.push(event);
}
}Aggregate 는 이벤트를 발행하는 주체이다. 도메인 이벤트이기 때문에 도메인이 이벤트를 발행하는 것이 맞다고 생각한다.
Egg 도메인 객체에서 알이 부화하는 로직이 실행되면, publishEvent를 호출하여 이벤트를 발행한다.
export class Egg extends Aggregate<Egg> {
// ...
hatch(hatchedAt: Date, weight: number) {
this.status = 'HATCHED';
this.hatchedAt = hatchedAt;
this.hatchedWeight = weight;
this.publishEvent(new EggHatchedEvent(
this.id,
this.hatchedAt,
this.hatchedWeight,
this.speciesId,
this.pairId,
this.fatherId,
this.motherId,
this.inbreedingCoefficient
))
}
}이 배열에 담긴 이벤트들은 aggregate가 저장될 때 같이 저장되게 된다.
export abstract class Repository<T extends Aggregate<T>> {
// ...
async save(entities: T[]) {
// ...
// aggregate를 저장 후 event를 저장한다.
await this.getEntityManager().persist(entities).flush();
await this.saveEvents(entities.flatMap((entity)=> entity.getPublishedEvents()));
}
async saveEvents(events:DomainEvent[]){
// event store에 발행된 이벤트들을 넣는다.
this.context.get(EVENT_STORE).push(...events)
return this.getEntityManager().persist(events).flush();
}
}그리고 트랜잭션을 위한 @Transactional() 데코레이터에서는 어플리케이션 메서드가 실행이 완료되면 위에서 담긴 이벤트 스토어를 실행시킨다.
// mikroORM의 Transactional을 매핑한 데코레이터
export function Transactional(options?: TransactionOptions) {
return function (target: DddService, propertyKey: string, descriptor: PropertyDescriptor) {
// ...
descriptor.value = async function (this: DddService, ...args: any[]) {
// ...
const storedEvents = this.context.get(EVENT_STORE);
this.context.set(EVENT_STORE, []);
eventStore.handleEvents(storedEvents);
return result;
};
return descriptor;
};
}
eventStore의 handleEvents를 통해 이벤트를 처리한다.
export class EventStore {
private subject = new Subject<DomainEvent>();
handleEvents(events: DomainEvent[]){
events.forEach((event)=> this.subject.next(event));
}
// 서버가 구동됨과 동시에 시작하여 subject를 구독한다.
async start(){
this.subject.pipe(
concatMap(async (event)=>{
// ...event handler를 가져오고 핸들러 전용 context를 만들고 entityManager를 주입하는 동작
// event handler를 실행한다.
await service[serviceMethod].call(service, event)
})
)
}
}이렇게 하면 발행한 이벤트가 등록된 핸들러를 호출하는 로직까지 완성된다.
이벤트 구독
다만, 아직 우리는 핸들러를 등록하는 코드를 본적이 없다.
export function EventHandler<T extends DomainEvent>(
eventClass: new (...args: any[]) => T,
options?: { description?: string; },
) {
return function (target: any, propertyKey: string, _: PropertyDescriptor) {
// ... event class, service class, method 등 정보를 핸들러 목록에 주입한다.
};
}구독하는 곳에서는 이렇게 사용하면 된다.
export class ParrotService extends ApplicationService {
// ...
@EventHandler(EggHatchedEvent,{
description: '알이 부화했을 때 유조를 등록한다.'
})
@Transactional()
async registerChick(event: EggHatchedEvent){
const { eggId, hatchedAt, hatchedWeight, speciesId, pairId, fatherId, motherId, inbreedingCoefficient } = event;
const chick = Parrot.fromHatched( ... )
await this.parrotRepository.save(chick);
}
}비교
정리하면,
- 도메인이 이벤트를 발행하고
- 트랜잭션 커밋 이후 이벤트를 디스패치하며
- RxJS concatMap을 사용하여 순서를 보장해 처리한다.
라고 할 수 있다. 이제 기존 코드와 비교해보자.
class EggService {
@Transactional()
async hatch(eggId: string, hatchedAt: Date) {
// 1. 알 조회 (Read)
const egg = await this.eggRepository.findOneOrFail(eggId);
// 2. 알 부화 상태로 업데이트 (Update)
egg.hatch(hatchedAt);
await this.eggRepository.save(egg);
// 3. 유조 생성 (Create)
const chick = new Parrot({
type: "Chick",
eggId,
bornAt: hatchedAt,
// ...
});
await this.parrotRepository.save(chick);
}
}도메인 이벤트를 사용하지 않은 코드. 절차지향적이다.
// eggService.ts
class EggService {
@Transactional()
async hatch(eggId: string, hatchedAt: Date) {
const egg = await this.eggRepository.findOneOrFail(eggId);
egg.hatch(hatchedAt);
await this.eggRepository.save(egg);
}
}
// parrotService.ts
class ParrotService {
@EventHandler(EggHatchedEvent,{
description: '알이 부화했을 때 유조를 등록한다.'
})
@Transactional()
async registerChick(event: EggHatchedEvent){
const { eggId, hatchedAt, hatchedWeight, speciesId, pairId, fatherId, motherId, inbreedingCoefficient } = event;
const chick = Parrot.fromHatched( /* ... */ )
await this.parrotRepository.save(chick);
}
}도메인 이벤트를 사용한 코드. 유조와 관련된건 ParrotService로, 부화는 EggService로 책임이 분리되었다.
기존의 절차지향적인 코드가 전체적인 코드의 흐름은 파악하기 더 쉬웠을지도 모른다. 다만 이는 책임분리의 이점이 아닌 단순히 코드의 흐름을 파악하기 쉬운 것일 뿐이다.
추후에 부화가 되었을 때 추가적인 요구사항이 생기고, 기존의 것들을 수정하게 되었을때 전과 같은 코드는 수정을 하기위해 투여하는 생각의 리소스를 많이 사용해야한다.
“이걸 추가하면 기존 로직에서 변경되는건 없을까?”, “여기에 추가하면 될까?” 와 같은 고민들 말이다.
코드 자체의 가독성도 높아졌다고 생각한다. 명시적으로 EggHatchedEvent를 핸들링한다고 써있고 그 아래 description으로 조금 더 자세하게 쓸 수 있다.
이런 부분에서 나는 표현력을 조금 더 극대화 했다고 생각한다.
인메모리 이벤트 방식의 한계
물론 이렇게 하면 아주 쉽게 단점을 찾을 수 있다. 바로 이벤트가 “인메모리 방식”으로 발생한다는 것이다.
메모리상에 있으면 빠른거 아니냐? 라고 생각할 수 있지만 문제는 휘발성이다. 서버가 다운되어 버리면 그냥 날아가 버리는 것이다.
만약 알 부화 로직이 끝나고 이벤트가 발행되었는데 핸들러가 유조를 등록하기 직전에 서버가 다운되면 어떻게 될까? 이벤트는 메모리 상에서 처리 중이었기 때문에 그대로 날아가 버리고, 알은 부화했지만 새끼는 등록되지 않은 정합성 오류가 발생하게 된다.
그래서 앞서 코드에서 보여준 것처럼 이벤트를 메모리에 띄우기 전에 데이터베이스에 물리적으로 먼저 저장하는 방식을 택했다.
일종의 Outbox 패턴이라고 할 수 있다.
이렇게하면 설령 서버가 죽어서 이벤트가 메모리에서 날아가더라도, 재기동 후 재처리할 수 있다.
이벤트가 DB에 저장이 되고, 각 이벤트는 pending, completed, failed 상태를 가질 수 있다.
서버가 다시 켜지면 pending, failed 상태의 이벤트를 다시 읽어와 순차 처리할 수 있도록 하면 된다. 이때 중복실행이 될 수 있으므로(실제로는 성공했지만 completed로 저장하는 순간 서버가 다운되면 pending으로 남아있을 것이다.)
이벤트 핸들러는 멱등성을 지키도록 작성해야한다.
예를 들어 유조 생성 시 이미 생성되었는지 체크하는 로직을 추가하거나 하는 식으로 말이다.
최소한의 데이터 정합성을 위한 안전장치라고 보면 된다.
마무리

흔히 DDD나 도메인 이벤트는 대규모 팀, 혹은 MSA 환경에서나 쓰는 화려한 기술이라고 생각한다. 하지만 혼자서 모든 것을 설계하고 개발하는 환경에서 오히려 이 패턴들이 더 큰 힘을 발휘할 때가 있다.
굳이 “많은 사람들이 사용하기 때문에”, “MSA니까”와 같은 이유가 아닌,
“복잡한 도메인 로직을 분리해서 유지보수를 쉽게 하기 위해”라고 생각하면 더 좋을 것이다. 이전에 근무했던 조직(유능한 개발자들이 많은 회사였다.)에서도 비슷한 접근을 사용한 적이 있어 더 익숙하게 느껴졌다.
물론 거기서는 kafka도 사용하고 있었고, 지금과는 조금 다른 방식으로 사용하고 있었기에 현재의 나의 상황과는 다르지만 말이다.
도메인이 복잡해질수록 코드가 비즈니스의 현실 세계를 투영하기위해 복잡해진다. 다만, 이 복잡성을 최대한 깔끔하게 풀어내도록 노력해야 한다는 점은 같다.
그렇지 않으면, 결국 “스파게티 코드”가 되어버려 나 자신조차 이 코드가 왜 이렇게 작성되어있는지, 어떤 로직인지 이해하지 못할 수 있다.
나비어리 시스템을 만들면서 내가 가장 지키고 싶은 철학은 “현실 세계의 복잡함을 깔끔하게 풀어내는 것”이다.
개발만 하지 않기에 개발 생산성이 더욱 중요하다고 생각한다. 이런 고민의 흔적들이 훗날 이 시스템을 유지보수할 나 자신에게 큰 도움이 되기를 바라며 이 글을 마친다.