나비어리 시스템 개발기 #2: 백엔드 - 기술 스택

들어가며
나비어리 시스템 설계를 하며 저번 글 에서 다루었던 언어 선택에 이어 이번에는 기술 스택을 선택한 과정을 정리해보려고 한다.
프레임워크 선택과정과 추가적인 라이브러리 선택에 대한 내용을 다룬다.
프레임워크 및 런타임 - Bun + Elysia
Bun
사실 Bun을 직접 선택했다기보단 Elysia 프레임워크를 사용하기 위해 선택한 측면이 크다.
Bun의 경우 속도를 굉장히 강조하지만, 나에게는 속도 자체는 그렇게 중요하진 않았다. 일단 나 혼자 쓰는 것이기도 하고 SaaS로 판매할 경우에도 사용자가 많지 않을 것이라고 생각한다.(대부분 사용자가 10명 안쪽일 테니까.)
또한 앵무새라는 생물 자체를 다루는 것이다보니 데이터의 양 또한 그렇게 많지 않아 일단은 내 기능에서 속도가 문제될만한 부분은 없다고 생각했다.
Bun을 선택하고 가장 좋다고 느끼는 점은 Bun 자체가 제공하는 기능들이 굉장히 많다는 점이다. (최근 claude를 만든 회사인 Anthropic에서 Bun을 인수했다는 소식을 들었다. 이것도 긍정적인 소식이라 좋다 ㅎㅎ)
일단, 가장 좋았던 것은 UUID, crypto, test runner 의 기능들을 bun 내부 API로 제공한다는 것이 마음에 들었다.
UUID
나의 경우 대부분의 프로젝트에서 ID는 UUID v7을 사용한다. v4와 같은 완전한 랜덤값은 DB 저장 시 인덱싱에 성능 문제가 있기 때문에 v7을 사용한다. (물론 위에서 성능은 상관없다라고는 했지만 그래도 좋은게 좋은거 아니겠나 ㅎㅎ)
Node.js의 경우 uuid 라이브러리를 설치해야 하지만 bun은 기본적으로 내장되어있어 바로 사용할 수 있다.
import { randomUUIDv7 } from "bun";Crypto
또한 crypto 역시 비밀번호를 hash할때 사용하기 좋다. bcrypt 같은것도 내장되어있기 때문에 바로 사용 가능하다
Bun.password.hash(password, "bcrypt");test runner
Bun에서 가장 만족하는 기능이다. jest, vitest와 같은 도구들을 사용해도 되긴 하지만(기존 프로젝트들은 대부분 jest를 사용했고 최근에는 vitest를 사용했었다.), bun 역시 가볍고 빠른 테스트 러너를 갖고 있고 대부분 jest와 사용법이 비슷하기 때문에 적응할 필요도 없었다.
물론 내가 class mocking할 때 자주쓰는 jest.mocked 는 따로 없어서 내가 따로 구현하긴했다.
import { describe, expect, test } from "bun:test";
import { mocked } from "./mock";
class TestClass {
testMethod() {
return "test";
}
}
describe("mocked 테스트", () => {
test("객체를 모킹할 수 있다.", () => {
const instance = new TestClass();
expect(instance.testMethod()).toBe("test");
const mockedInstance = mocked(instance);
mockedInstance.testMethod.mockReturnValue("mocked");
expect(mockedInstance.testMethod()).toBe("mocked");
});
});따로 구현한 mocked 함수를 테스트하는 코드
Elysia
많은 사람들이 이 프레임워크에 대해 생소하다고 느낄 수 있다고 생각한다. 나 역시도 처음 들어보는 프레임워크였고, 찾아보면서 내 요구사항에 적합하다고 생각되어 선택했고, 이것이 Bun을 선택하게 된 주된 이유이기도 하다.
기준
일단 프레임워크를 고르는 기준은 명확했다. 내가 잘 다룰 수 있어야하고, 최대한 귀찮게 하지 않아야한다.
-
DI는 내가 알아서 한다
NestJS와 같이 DI를 강제하는 프레임워크의 경우 DI 컨테이너를 내가 마음대로 접근하여 수정할 수 없게 되어있기 때문에 컨텍스트를 커스터마이징 한다거나 AOP 기능을 추가한다거나 하기 어렵다. (물론 ALS과 같은 기능을 사용하면 된다지만.. 애초에 앵귤러의 모듈 시스템을 좋아하지 않기도 하고.. 그냥 난 Nest를 좋아하지 않을지도..)
Elysia의 경우 DI를 강제하지 않고, 구조가 굉장히 단순하다. 여러개의 Elysia 인스턴스를 생성해 조합하여 사용하는 Composition Pattern을 사용하여, 커스터마이징이 용이하고 module 개념으로도 사용이 가능하다. 또한 각 모듈간의 타입시스템이 매우 잘되어 있어 타입 안정성이 매우 뛰어나다.
export const post = publicRouter() .decorate("userService", Container.get(UserService)) .post( "/sign-up", async ({ userService, body }) => { // destructure const { code, name, password, phone } = body; // set params const params: Parameters<UserService["signUp"]> = [ code, { name, password, phone }, ]; // call services await userService.signUp(...params); // return response return { data: {} }; }, { body: userSignUpCommand, response: { 200: t.Object({ data: t.Object({}), }), }, tags: ["User"], detail: { description: "유저 회원가입 API", }, }, );단순화한 회원가입 API 예시
-
API 문서가 자동으로 생성되어야 한다
API 문서는 항상 최신 상태로 유지되어야한다. 이를 위해 Swagger와 같은 도구를 사용하는데, express 같은 경우 swagger를 jsdoc으로 작성하여 사용하거나 한다. 이는 jsdoc을 통해 자동으로 생성해주지만 그렇다고 자동으로 내가 수정한 output이 반영되지는 않는다. output이 수정됨에 따라 jsdoc을 다시 수정해줘야한다. 이는 매우 귀찮은 작업이고 초기 프로젝트의 경우 매우 큰 확률로 놓치게 된다.
개발자로 일할 때에는 항상 validation schema를 읽어 swagger 문서를 만들어 주는 도구를 사용했었다. 사이드 프로젝트에서는 그렇지 않은 언어, 프레임워크를 사용했었는데 항상 문서의 최신화가 문제가 되었다.
Elysia의 경우 validation schema를 통해 API 문서를 자동으로 생성해준다.
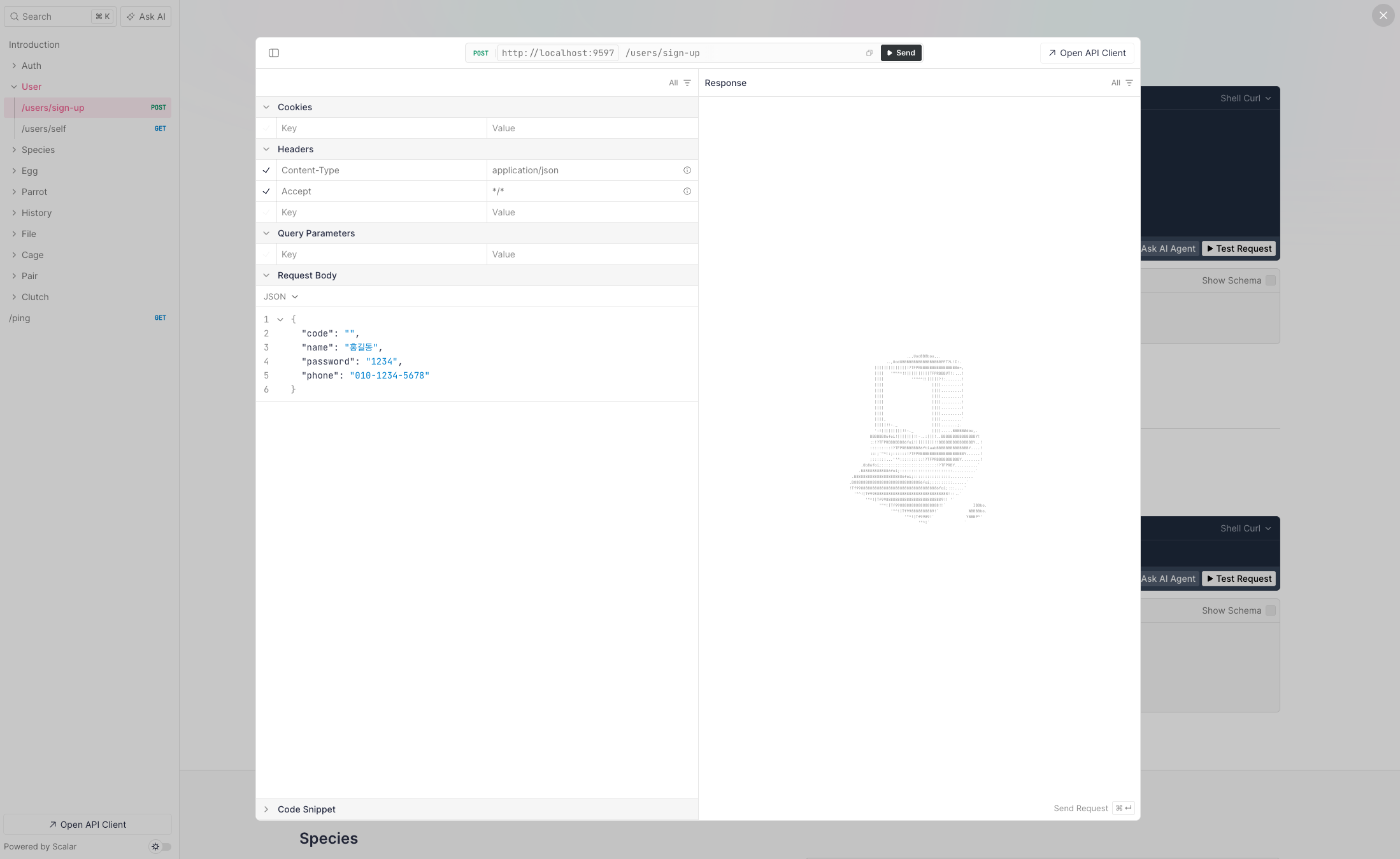
현재 구현된 API 문서 사진
위 두가지는 나에게 굉장히 중요한 요소였지만, 두가지를 모두 채워줄 수 있는 프레임워크는 찾기 어려웠다. 대부분의 프레임워크는 둘중 한가지만 만족하거나 다른 라이브러리에 의존해야했지만, 해당 라이브러리들도 유지보수가 잘 되지 않았다.
물론 Elysia도 완벽한 프레임워크는 아니다. 1명의 개발자가 메인테이너로 프로젝트를 이끌어 가고 있어서 굉장히 불안정한 상태이다. 그럼에도 위의 부분들이 나에게 큰 만족감으로 다가왔고, Elysia로 선택했다.
Database & ORM - MySQL + MikroORM
MySQL
데이터베이스는 처음에 PostgreSQL을 사용하려고 했었다. 하지만 나는 명령어에 익숙해지기까지 시간이 걸렸고, mysql 처럼 빠르게 사용하기 어려웠다.
PostgreSQL은 \d, \dt 와 같은 명령어를 사용해서 SQL을 대신할 수 있어 빠르긴 했지만, 초기 프로젝트 특성상 데이터베이스를 자주 보거나 변경해야했고, 아직 익숙하지 않은 나에게는 조금 불편하다고 생각했기 때문에 그래서 mysql로 마이그레이션을 진행했다. (물론 둘다 SQL을 사용하기 때문에 )
MikroORM
ORM 역시 상황은 마찬가지였다. 기존에 선택지는 2가지중 하나였었다. TypeORM과 Prisma였다. TypeORM은 내가 가장 잘 알고 잘 사용할 줄 아는 ORM이었지만, 기본적으로 신뢰하기 어렵다고 생각했다. 개발자로 일할 당시 버그 때문에 고생했는데 파고들어가다 보니 TypeORM의 bigint 관련된 기능에 버그가 있다는 것을 알아냈고, bug report를 했지만 10개월 정도 방치되다가 결국 TypeORM 측에서 이슈 해결 포기를 선언하면서 close되어버렸다.
그외에도 여러가지 이슈들도 있었고, 로깅이나 이런부분에서도 TypeORM 설계상 어려운 부분이 있다고 생각했다. 2026년 상반기에 1.0을 목표로 현재는 다시 활발하게 개발을 진행하고 있는 것 같지만.. 개인적인 경험때문에 사용하고 싶지 않았다.
그래서 처음엔 Prisma를 사용했었다. Prisma는 schema를 작성 후 code generation을 통해 해당 모델의 타입을 생성하고 사용하는 방식이다. 이를 통해 타입안정성을 확보할 수 있고 도메인 모델의 순수성을 보장 할 수 있다는 장점이 있었다.
하지만 Prisma는 몇가지 단점이 있었다.
첫번째는 Prisma schema를 작성할 경우 도메인의 순수성은 올라간다지만 DDD를 위해 도메인 모델을 풍부하게 가져가게 될 때 엔티티와 분리되면서 개발 복잡도가 올라가고 생산성이 낮아진다. 초기 프로젝트에서 설계를 하면서 동시에 개발도 진행되었기 때문에 도메인 수정이 여러번 일어나게 되는데, 도메인 모델을 수정하고 Prisma schema를 수정하고 code generation을 하는 과정이 굉장히 번거로웠다.
두번째는 내가 부족해서인지 모르겠지만, 기존에 TypeORM에서 사용하던 @transactional 데코레이터를 Prisma에서는 구현하기 어려웠다.
세번째는 쿼리빌더가 없다는 점이었다. 나는 웬만하면 ORM 처럼 사용하려고 하지만, 대시보드 특성상 복잡한 쿼리를 사용해야하는 경우가 가끔 있는데, 이부분에서 raw query를 사용하기 싫었다.
그래서 결국 다른 ORM을 찾아보다가 MikroORM을 발견하게 되었다. MikroORM은 몇년전에 처음 봤었는데 그때는 기능이 그렇게 많지는 않았었고, TypeORM을 잘 사용하고 있었기 때문에 그렇게 눈여겨 보지 않았다.
하지만 지금은 꽤나 기능도 많아졌고, TypeORM처럼 사용할 수 있지만 typeORM의 단점들을 극복한 ORM이라고 생각한다.
또한, prisma에서 단점이라고 생각되었던 entity와 schema를 분리하는 방식이 아니라 typeORM처럼 entity와 schema를 분리하지 않고도 DDD를 구현할 수 있다는 점도 마음에 들었다.
이론적으로 완벽하면서도 실용적인 선택이 있다면 당연히 그것을 택하겠지만, 초기 프로젝트에서 순수한 DDD를 고집하는 것은 생산성 측면에서 좋은 선택이 아닐 수 있다. MikroORM은 이 둘 사이의 적절한 균형점을 제공한다.
마무리
브리딩 시스템을 개발하기 위해 아래와 같이 기술스택을 선택했다
- Runtime: Bun, 내장 기능 다양
- Web Framework: Elysia, 자동 문서화와 유연한 프레임워크 구조
- Database: MySQL, 익숙함과 실용성
- ORM: MikroORM, TypeORM의 단점들을 극복한 ORM
물론 이것들이 완벽한 선택이라고는 말하지 않겠다.
Bun의 경우 아직 major version이 1이 되지 않은 zig로 만들어져있고(zig도 공부해봤는데 zig는 minor 버전이 변경될때마다 breaking change가 일어나서 LLM 학습도 어렵고 사용자 역시 매번 change log를 봐야한다..) bun 역시 아직 100% node를 대체할 수 있다고 생각되지는 않는다.
Elysia 역시 메인테이너가 한명이라 메인테이너가 버리면 오픈소스 특성상 유지보수가 어려워질 수 있다는 점도 고려해야한다.
MikroORM의 경우 커뮤니티가 아직은 TypeORM, Prisma와 같은 ORM들과 비교해선 훨씬 작고 레퍼런스도 많이 적다.
그럼에도 불구하고 1인 개발 환경에서 “나에게 맞는 도구”를 찾기 위해 노력했다고 생각한다.
나는 개발을 하면서 항상 내가 그것을 선택한 이유가 명확해야 한다고 생각한다. 물론 나 역시 해당 프레임워크가 핫하다는 이유로 많이 선택해봤고 그 중 꽤나 잘 맞아서 아직도 사용중인 라이브러리들도 있다.
이유가 어찌됐건 나에게 잘 맞는, 내가 생산성을 최대로 뽑아낼 수 있는 도구들을 선택하고 그것을 사용하는 것이 중요하다고 생각한다.
다음 글 에서는 도메인 모델 설계에 대해 다뤄보겠다.