Naviary System Development #4: Backend - Maximizing Expressiveness with Domain Events

Introduction
The foundation of backend development is CRUD. Creating, Reading, Updating, and Deleting data is the fundamental responsibility of a backend application.
Most web services consist of a massive repetition of these CRUD operations.
Naviary is no different. “When an egg hatches, chick data is created.”
It’s simple. You just update the egg to a hatched state and then create the chick data.
The simplest way to implement this would look like the following:
class EggService {
@Transactional()
async hatch(eggId: string, hatchedAt: Date) {
// 1. Read egg
const egg = await this.eggRepository.findOneOrFail(eggId);
// 2. Update egg to hatched state
egg.hatch(hatchedAt);
await this.eggRepository.save(egg);
// 3. Create chick
const chick = new Parrot({
type: "Chick",
eggId,
bornAt: hatchedAt,
// ...
});
await this.parrotRepository.save(chick);
// 4. Increase breeding success count for parent pair
const pair = await this.pairRepository.findById(egg.pairId);
pair.increaseBreedingSuccessCount();
await this.pairRepository.save(pair);
}
}
The functionality works. However, something feels uncomfortable. As covered in the previous article , Parrot and Egg are distinctly different aggregate roots.
The domain of the breeding system is to express the continuous process of the real world in the digital world. An egg hatching does not simply mean changing the state of the egg; it results in a series of chain reactions (Side Effects) across various domains, such as the birth of a new organism and the update of the parents’ history.
Of course, I am not doing MSA, nor am I someone who feels uncomfortable injecting ParrotRepository into EggService. But EggService being the subject that creates a Parrot and updates the history of the parent pair…? Hmm… this feels a bit uncomfortable.
The coupling becomes too tight, and it turns into a procedural script. And the domain logic of “an egg hatching leading to a chick being registered” is not expressed that way.
In backend application design through DDD, using Domain Events can excellently express these side effects.
The goal of backend design in Naviary is not “performance” or “making code look pretty.” It is cleanly unwinding the complexity of the real world.
I wanted the code to directly speak the series of flows such as egg hatching, chick birth, growth, and mating. And I believed the domain itself should declare the subject of the event issuance.
A structure where the system doesn’t say, “This egg hatched!” but the egg itself says, “I hatched!”
What is a Domain Event?
As the name suggests, a Domain Event means a “meaningful incident that occurred in the domain.” Because it is a fact that has already happened, it is usually expressed in the past tense.
-
EggHatchEvent(X) ->EggHatchedEvent(O) : The egg hatched. -
PairRegisterEvent(X) ->PairRegisteredEvent(O) : The pair was registered.
Because you are recording a fact that has already occurred, you do not change or cancel it; you simply propagate to the system, “This happened to me!”
We tend to think of Side Effects only as bad things, but in reality, they can be divided into predicted side effects and unpredicted side effects.
In this case, it becomes very easy to handle the predicted Side Effect of this domain event. The Egg domain notifies that it has hatched, and when the Chick domain hears the fact that the egg has hatched, it simply creates a chick according to that information.
This loose coupling shines more as the system grows larger and the domain becomes more complex. Even if a requirement stating “Send an alert to those on the waitlist when an egg hatches” is added later, you don’t need to modify EggService or other existing code; you simply create one method that subscribes to EggHatchedEvent.
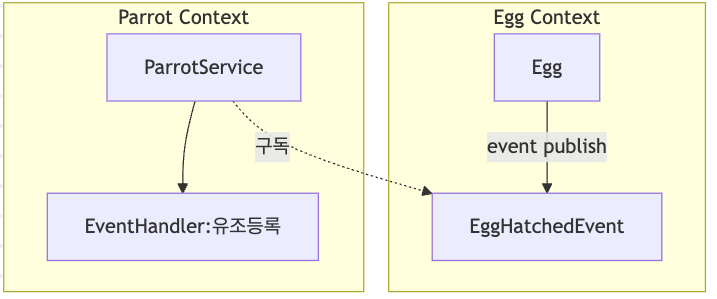
Domain Event Modeling in Naviary
Then how should we express this event? First of all, in the Naviary system, events are not just published as volatile data in memory. I designed the structure so they could be stored as trackable data.
@Entity({abstract: true, discriminatorColumn: 'type'})
export abstract class DomainEvent {
@PrimaryKey()
protected id!: number;
@Property()
type: string;
// Payload containing actual real data of the event
@Property({ type: 'text' })
protected data!: string;
constructor() {
this.type = this.constructor.name;
this.occurredAt = new Date();
}
// ...
}
The reason I set it as an entity is exactly what I mentioned above—to allow volatile data to be tracked. Of course, tracking would be nearly impossible in a structure where data piles up crazily (in such companies they wouldn’t use memory-based events anyway, they would use Kafka or another message queue…).
I’m not worried about data piling up to that extent, so I decided to proceed with this for now.
Based on this, if we look at creating the actual hatching event:
export class EggHatchedEvent extends DomainEvent {
constructor(
public eggId: string,
public hatchedAt: Date,
public hatchedWeight: number,
public speciesId: number,
public pairId: string,
public fatherId: string,
public motherId: string,
public inbreedingCoefficient: number
){
super()
}
}
EggHatchedEvent contains all the context needed at the time of hatching. Through the event, we can now know pieces of information such as which egg it is, when it hatched, how many grams it weighs, and who its parents are.
How to Publish and Subscribe to Events
I know that we will load them in memory and store them in the DB to prepare for unknown situations, and that they contain trackable and meaningful data. There’s only one question left.
“Who processes this event, when, and within what transaction boundary?”
Often when speaking of Event-Driven Architecture (EDA), people think of message brokers like Kafka or RabbitMQ. I also really want to use them, but considering the cost and the resources required for maintenance, I think it is the absolute peak of over-engineering.
Of course I could operate it, but my main job now is a breeder and a businessperson, not a software developer. It might be different if I plan to make it a SaaS later, but I don’t want to make maintenance difficult by building such a massive system for what is effectively a personal business.
The tool I chose was RxJS. RxJS is a library for reactive programming, specialized in handling asynchronous data as streams.
Furthermore, by using RxJS’s concatMap, events can be processed in the order they were published, and transaction boundaries can be maintained.
Event Publication
export abstract class Aggregate<T> {
// ...
private events?: DomainEvent[]
protected publishEvent(event: DomainEvent) {
this.events = this.events ?? [];
this.events.push(event);
}
}
Aggregate is the subject that publishes the event. Because they are domain events, I believe it’s correct for the domain to publish the events.
When the logic for the egg hatching gets executed in the Egg domain object, it calls publishEvent to publish the event.
export class Egg extends Aggregate<Egg> {
// ...
hatch(hatchedAt: Date, weight: number) {
this.status = 'HATCHED';
this.hatchedAt = hatchedAt;
this.hatchedWeight = weight;
this.publishEvent(new EggHatchedEvent(
this.id,
this.hatchedAt,
this.hatchedWeight,
this.speciesId,
this.pairId,
this.fatherId,
this.motherId,
this.inbreedingCoefficient
))
}
}
The events contained in this array will be saved together when the aggregate is saved.
export abstract class Repository<T extends Aggregate<T>> {
// ...
async save(entities: T[]) {
// ...
// Save events after saving aggregate
await this.getEntityManager().persist(entities).flush();
await this.saveEvents(entities.flatMap((entity)=> entity.getPublishedEvents()));
}
async saveEvents(events:DomainEvent[]){
// Put published events into the event store
this.context.get(EVENT_STORE).push(...events)
return this.getEntityManager().persist(events).flush();
}
}
And in the @Transactional() decorator used for transactions, the event store filled above is executed when the application method finishes executing.
// Decorator mapping mikroORM's Transactional
export function Transactional(options?: TransactionOptions) {
return function (target: DddService, propertyKey: string, descriptor: PropertyDescriptor) {
// ...
descriptor.value = async function (this: DddService, ...args: any[]) {
// ...
const storedEvents = this.context.get(EVENT_STORE);
this.context.set(EVENT_STORE, []);
eventStore.handleEvents(storedEvents);
return result;
};
return descriptor;
};
}
The events are processed through the EventStore’s handleEvents.
export class EventStore {
private subject = new Subject<DomainEvent>();
handleEvents(events: DomainEvent[]){
events.forEach((event)=> this.subject.next(event));
}
// Starts concurrently with server initialization and subscribes to the subject
async start(){
this.subject.pipe(
concatMap(async (event)=>{
// ...action of getting event handler, creating handler-specific context and injecting entityManager
// Execute event handler
await service[serviceMethod].call(service, event)
})
)
}
}
This completes the logic up to calling the handler registered for the published event.
Event Subscription
However, we haven’t seen the code for registering the handler yet.
export function EventHandler<T extends DomainEvent>(
eventClass: new (...args: any[]) => T,
options?: { description?: string; },
) {
return function (target: any, propertyKey: string, _: PropertyDescriptor) {
// ... inject information such as event class, service class, method, etc. into the handler list.
};
}
You can use it like this where you want to subscribe.
export class ParrotService extends ApplicationService {
// ...
@EventHandler(EggHatchedEvent,{
description: 'Registers a chick when an egg hatches.'
})
@Transactional()
async registerChick(event: EggHatchedEvent){
const { eggId, hatchedAt, hatchedWeight, speciesId, pairId, fatherId, motherId, inbreedingCoefficient } = event;
const chick = Parrot.fromHatched( /* ... */ )
await this.parrotRepository.save(chick);
}
}
Comparison
To summarize,
- The domain publishes the event.
- The event is dispatched after the transaction commits.
- RxJS’s
concatMapis used to process them, ensuring sequence.
Now let’s compare it with the existing code.
class EggService {
@Transactional()
async hatch(eggId: string, hatchedAt: Date) {
// 1. Read egg
const egg = await this.eggRepository.findOneOrFail(eggId);
// 2. Update egg to hatched state
egg.hatch(hatchedAt);
await this.eggRepository.save(egg);
// 3. Create chick
const chick = new Parrot({
type: "Chick",
eggId,
bornAt: hatchedAt,
// ...
});
await this.parrotRepository.save(chick);
}
}
Code without domain events. It is procedural.
// eggService.ts
class EggService {
@Transactional()
async hatch(eggId: string, hatchedAt: Date) {
const egg = await this.eggRepository.findOneOrFail(eggId);
egg.hatch(hatchedAt);
await this.eggRepository.save(egg);
}
}
// parrotService.ts
class ParrotService {
@EventHandler(EggHatchedEvent,{
description: 'Registers a chick when an egg hatches.'
})
@Transactional()
async registerChick(event: EggHatchedEvent){
const { eggId, hatchedAt, hatchedWeight, speciesId, pairId, fatherId, motherId, inbreedingCoefficient } = event;
const chick = Parrot.fromHatched( /* ... */ )
await this.parrotRepository.save(chick);
}
}
Code using domain events. Responsibilities are separated; everything related to the chick goes to ParrotService, and hatching goes to EggService.
The existing procedural code might have made it easier to grasp the overall flow of the code. However, this is not an advantage of responsibility separation, but simply that the code flow is easier to understand.
Later, when new requirements arise upon hatching, and existing elements need to be modified, code like the earlier version requires you to spend a lot of mental resources to make those modifications.
Questions like, “If I add this, will anything change in the existing logic?” or “Should I add it here?”
I think the readability of the code itself has also improved. It explicitly states that it is handling EggHatchedEvent, and a slightly more detailed explanation can be written below it as a description.
In these aspects, I believe I have maximized expressiveness a little more.
Limitations of In-Memory Events
Of course, if you do it this way, you can find a downside very easily. It’s the fact that events occur in an “in-memory fashion.”
You might think, “If it’s in memory, isn’t it fast?” but the issue is volatility. If the server goes down, it simply vanishes.
What if the server goes down right after the egg hatching logic ends, the event is published, but just before the handler registers the chick? Because the event was being processed in memory, it just disappears, leading to a consistency error where the egg hatched but the chick isn’t registered.
That’s why I chose an approach where, as shown in the code earlier, the event is physically stored in the database first before hitting memory.
You could call it a sort of Outbox pattern.
By doing this, even if the server dies and the event vanishes from memory, it can be reprocessed after booting up again.
The event is saved in the DB, and each event can have a pending, completed, or failed state.
When the server turns back on, it can read events in the pending and failed states again and process them sequentially. Because duplicate execution is possible at this time (it might actually succeed but the server goes down at the exact moment of saving as completed, leaving it as pending),
the event handler must be written to ensure idempotency.
For instance, adding logic to check if a chick has already been created, and so on.
You can consider it a safeguard for achieving minimal data consistency.
Conclusion

Usually, people think of DDD or Domain Events as a fancy technology only used by large teams or in MSA environments. However, in an environment where you are designing and developing everything by yourself, there are times when these patterns exert even more power.
Rather than doing it because “many people use it” or “because it’s MSA,”
It is better to think of it as “to cleanly separate complex domain logic to make maintenance easier.” This approach is similar to what my previous company, (주)Ecube Labs , had adopted. (It was a company with many highly impressive developers whom I respect.)
Of course, they were also using Kafka, and using it in a slightly different manner from what I am showing now, so my current situation differs.
As the domain becomes more complex, the code becomes more complex to reflect the real world of the business. However, the point that you must strive to unwind this complexity as cleanly as possible remains the same.
Otherwise, it eventually becomes “spaghetti code,” to the point where even you yourself won’t be able to understand why the code is written the way it is or what the logic actually is.
The philosophy I want to uphold the most while building the Naviary system is “cleanly unwinding the complexity of the real world.”
Because I don’t just develop software, development productivity is even more important to me. I’ll conclude this article hoping that these traces of contemplation will be of great help to myself when maintaining this system in the future.