Naviary System Dev Diary #2: Backend - Tech Stack

Introduction
Following the previous post about language selection for the Naviary system, I’d like to summarize the process of choosing the tech stack this time.
In this post, I’ll cover the framework selection process and the choice of additional libraries.
Framework & Runtime - Bun + Elysia
Bun
In fact, I chose Bun more to use the Elysia framework than for Bun itself.
While Bun emphasizes speed, speed wasn’t that critical for me. I’m the only user for now, and even if I sell it as a SaaS, I don’t expect a huge number of users (probably fewer than 10 users in most cases).
Also, since it’s about parrots, the amount of data isn’t that large, so I didn’t think speed would be an issue for my features.
The best thing about choosing Bun is the sheer variety of built-in features it provides. (I heard that Anthropic, the company that created Claude, recently acquired Bun. This is great news! haha)
Specifically, I loved that features like UUID, crypto, and a test runner are provided as built-in Bun APIs.
UUID
In most of my projects, I use UUID v7 for IDs. I use v7 because completely random values like v4 can cause performance issues with indexing when stored in a database. (Of course, I said performance doesn’t matter much above, but better is still better, right? haha)
In Node.js, you have to install a uuid library, but in Bun, it’s built-in and ready to use.
import { randomUUIDv7 } from "bun";Crypto
crypto is also great for hashing passwords. Since things like bcrypt are built-in, you can use them immediately.
Bun.password.hash(password, "bcrypt");Test Runner
This is my favorite feature in Bun. While tools like Jest or Vitest are fine (I used Jest for most previous projects and Vitest recently), Bun has a lightweight and fast test runner. Since its usage is very similar to Jest, there was no learning curve.
One thing missing was jest.mocked, which I frequently use for class mocking, so I implemented it myself.
import { describe, expect, test } from "bun:test";
import { mocked } from "./mock";
class TestClass {
testMethod() {
return "test";
}
}
describe("mocked test", () => {
test("can mock an object", () => {
const instance = new TestClass();
expect(instance.testMethod()).toBe("test");
const mockedInstance = mocked(instance);
mockedInstance.testMethod.mockReturnValue("mocked");
expect(mockedInstance.testMethod()).toBe("mocked");
});
});Code testing the custom implemented mocked function
Elysia
Many people might find this framework unfamiliar. I also heard about it for the first time recently, but after researching, I found it fits my requirements perfectly. This was the main reason I chose Bun.
Criteria
My criteria for choosing a framework were clear: I must be able to handle it well, and it shouldn’t be cumbersome.
-
I’ll handle DI myself
Frameworks like NestJS that enforce DI make it difficult to access and modify the DI container as I please, which makes it hard to customize the context or add AOP features. (Of course, I could use features like ALS… but I’m not a big fan of Angular’s module system anyway… maybe I just don’t like Nest…)
Elysia doesn’t enforce DI and has a very simple structure. It uses a Composition Pattern where you combine multiple Elysia instances, making it easy to customize and use as common modules. Also, the type system between modules is excellent, providing high type safety.
export const post = publicRouter() .decorate("userService", Container.get(UserService)) .post( "/sign-up", async ({ userService, body }) => { // destructure const { code, name, password, phone } = body; // set params const params: Parameters<UserService["signUp"]> = [ code, { name, password, phone }, ]; // call services await userService.signUp(...params); // return response return { data: {} }; }, { body: userSignUpCommand, response: { 200: t.Object({ data: t.Object({}), }), }, tags: ["User"], detail: { description: "User sign-up API", }, }, );Simplified example of a sign-up API
-
Automatic API Documentation
API documentation should always be up-to-date. Tools like Swagger are used for this, and in Express, you’d often write Swagger using JSDoc. While JSDoc can generate documentation, it doesn’t automatically reflect changes in my output. As the output changes, I have to update the JSDoc. This is a tedious task and is very likely to be missed in the early stages of a project.
When working as a developer, I always used tools that read validation schemas to generate Swagger docs. In side projects where I used different languages/frameworks, keeping documentation updated was always a hassle.
Elysia automatically generates API documentation through validation schemas.
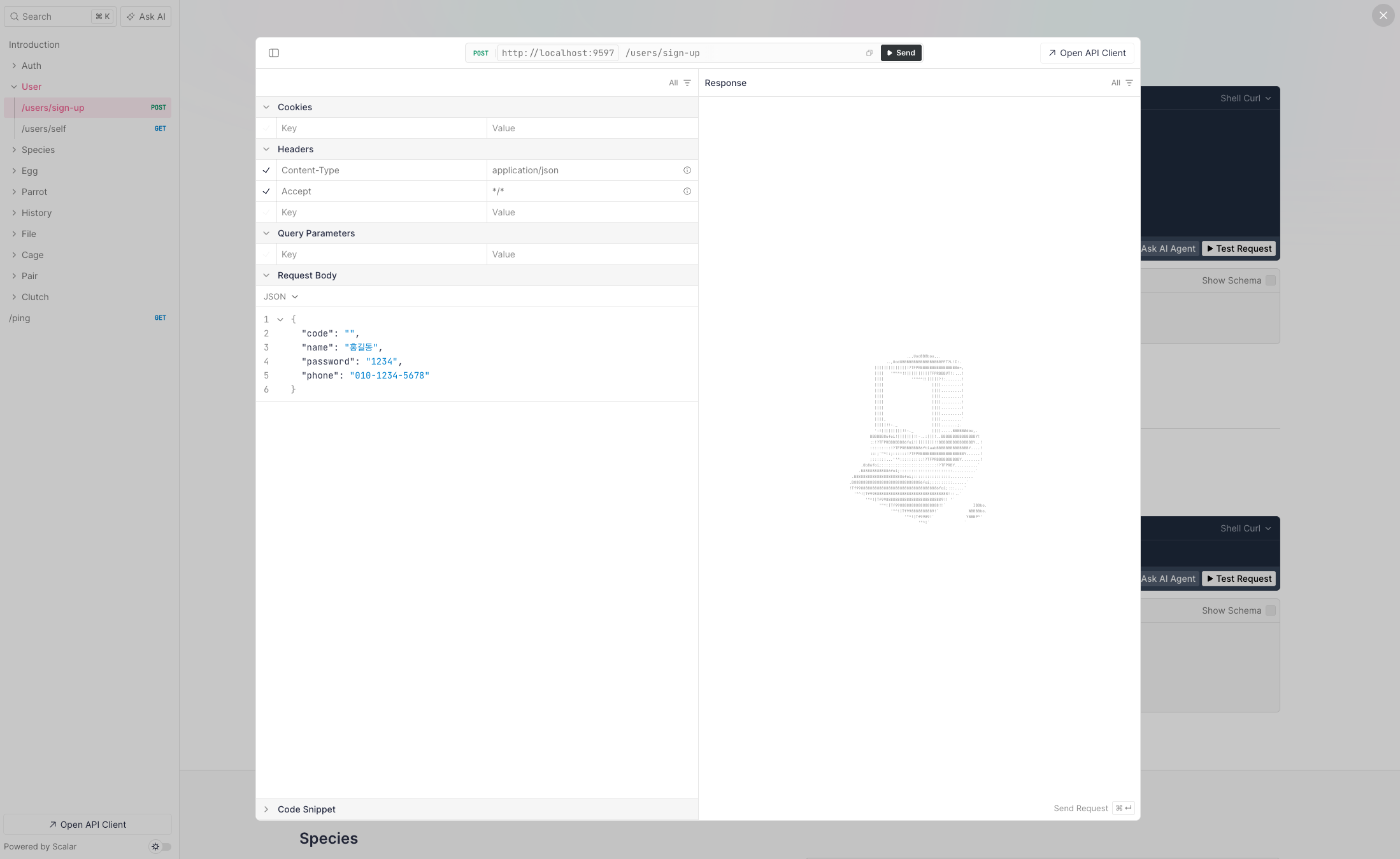
Screenshot of currently implemented API documentation
These two points were very important to me, but it was hard to find a framework that satisfied both. Most frameworks satisfied only one or required external libraries that weren’t well-maintained.
Of course, Elysia isn’t a perfect framework. It’s in a somewhat unstable state, led by a single main maintainer. Nevertheless, the features above gave me great satisfaction, so I chose Elysia.
Database & ORM - MySQL + MikroORM
MySQL
Initially, I planned to use PostgreSQL. However, it took some time to get used to its commands, and I couldn’t use it as quickly as MySQL.
While PostgreSQL allows replacing SQL with commands like \d and \dt, which is fast, the nature of an early-stage project meant frequent database inspection and changes. Since I’m not yet comfortable with it, I found it slightly inconvenient and migrated back to MySQL. (Of course, both use SQL anyway.)
MikroORM
The ORM situation was similar. Previously, the choices were usually TypeORM or Prisma. TypeORM was the ORM I knew best, but I found it fundamentally hard to trust. When working as a developer, I struggled with a bug, and upon digging deeper, I found it was a bug in TypeORM’s bigint-related functionality. I reported it, but it was neglected for about 10 months until TypeORM eventually closed it, admitting they couldn’t solve it.
There were other issues as well, and I felt that TypeORM’s design made things like logging difficult. While it seems development has become active again with a goal of 1.0 in the first half of 2026… my personal experience made me want to avoid it.
So I initially used Prisma. Prisma uses a method of generating types for models after writing a schema. This ensures type safety and guarantees the purity of the domain model.
However, Prisma had several drawbacks.
First, while writing a Prisma schema increases domain purity, separating it from entities as the domain model becomes richer for DDD increases development complexity and lowers productivity. In an early-stage project where design and development happen simultaneously, domain changes occur frequently. The process of modifying the domain model, updating the Prisma schema, and running code generation was extremely tedious.
Second, perhaps due to my own inadequacy, I found it difficult to implement the @transactional decorator I used to use in TypeORM within Prisma.
Third, it lacks a query builder. While I try to use ORMs as they are intended, dashboards sometimes require complex queries, and I didn’t want to use raw queries for those.
Eventually, I looked for other ORMs and discovered MikroORM. I had seen it a few years ago, but back then it didn’t have as many features, and I was using TypeORM well, so I didn’t pay much attention.
Now, it has plenty of features and is an ORM that can be used like TypeORM while overcoming TypeORM’s shortcomings.
Also, I liked that it allows implementing DDD without necessarily separating entities and schemas, unlike Prisma.
If there’s a choice that’s both theoretically perfect and practical, I’d obviously take it, but insisting on pure DDD in an early-stage project might not be the best choice for productivity. MikroORM provides a good balance between the two.
Conclusion
To develop the breeding system, I chose the following tech stack:
- Runtime: Bun, with diverse built-in features
- Web Framework: Elysia, for automatic documentation and a flexible structure
- Database: MySQL, for familiarity and practicality
- ORM: MikroORM, an ORM that overcomes TypeORM’s shortcomings
I won’t say these are perfect choices.
Bun is still made with Zig and hasn’t reached major version 1 yet (I studied Zig too, and Zig has breaking changes with every minor version change, making LLM training difficult and necessitating constant changelog checks…). I also don’t think Bun can 100% replace Node just yet.
For Elysia, one needs to consider the risk that the project is led by a single maintainer, and maintenance could become difficult if they walk away.
As for MikroORM, the community is still much smaller than TypeORM or Prisma, with far fewer references available.
Despite these factors, I believe I made an effort to find “tools that fit me” in a solo developer environment.
I believe there should always be a clear reason for choosing a technology. Of course, I’ve chosen many frameworks just because they were “hot,” and some of them fit so well that I’m still using them.
Regardless of the reason, choosing tools that fit me and allow me to maximize productivity is what matters most.
In the next post , I’ll talk about domain model design.